I’m Jose Omar Giraldo, a sound sound engineer from Colombia who is currently finishing a Master’s in Acoustic engineering. During mid-May and June I’ve been working with the Orcasound Team to improve an awesome active learning tool that was made by Diego and Kunal in the GSOC of the last year.
To introduce Orcasound briefly, they’re a team of scientists and coders that deploy hydrophones, which are microphones that capture sound underwater. Their goal is to monitor the Southern Resident Killer Whales, a very special type of orcas in terms of social behaviour.

This sensor network is streaming sound 24/7 and you can listen live here. As you can imagine, it is almost impossible for a human to be continuously listening for a whale call or other environmental noises that endanger their habitat. For this reason they’ve been developing computational approaches to analyze large databases of underwater recordings that leverage the detections to computers, but also they have teams working on the hydrophone nodes to improve the data acquisition device, in the general architecture of the app, and even in UX.

One of the things that I really like about Orcasound is that the team has people from very different backgrounds, ages, countries and they make you feel that you belong to the team almost instantly. I enjoy the meetings a lot because I always end up learning something new, either from whales, programming or life. We usually start with some ice breaker from Scott who usually leads the meetings, then we share the updates of our work and possible problems that we are facing.
They’re a very dynamic team and the discussions that emerge on the meetings provide us with very valuable feedback not only from the mentors, but also from the other students. I also think that these meetings promote the ability to present results and conclusions, and give a richer experience of developing software as a team. I do remember finding a bug in my code during the presentation that I wasn’t aware of when I was programming alone.
Going back to my project, a very important resource in order to evaluate algorithms, iterate and train models, is to have a labeled dataset, but again this process is very tedious in audio recordings, so the active learning tool was made to focus the time of the expert labelers into regions of audio that are going to be more useful to improve the detection model.
My goal is to improve the sampling of the audio regions that this tool presents for labeling, introducing metrics derived from the similarity of sounds. However this task of assessing sound similarity that is so trivial for humans, is a very complex one to do on computers. My strategy is to use embeddings, which are internal representations that a neural network builds to achieve a defined task. In this case, we have embeddings from neural networks that were trained to do sound classification in Audioset (the biggest environmental audio dataset) and humpback whale detection in a NOAA dataset.
Thanks to Google and the Tensorflow team we have these models easily available via tensorflow hub. So far I’ve been doing experiments with the embeddings of the vggish model that returns the shallower representation, and yamnet which is trained on the same dataset. I’ve been using another tool from tensorflow which is the embedding projector, where you can interactively visualize the possible clusters that are formed from the embeddings.
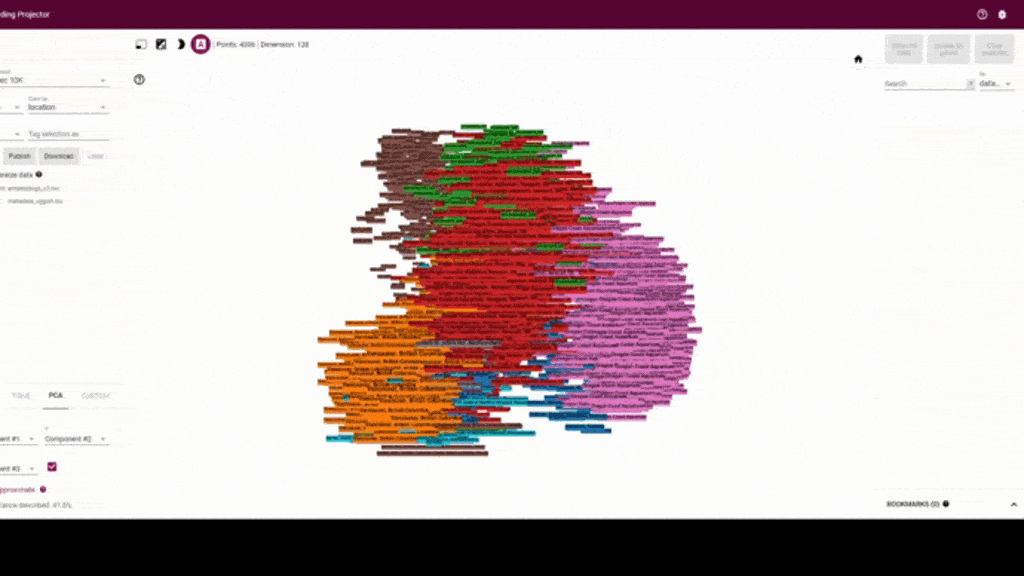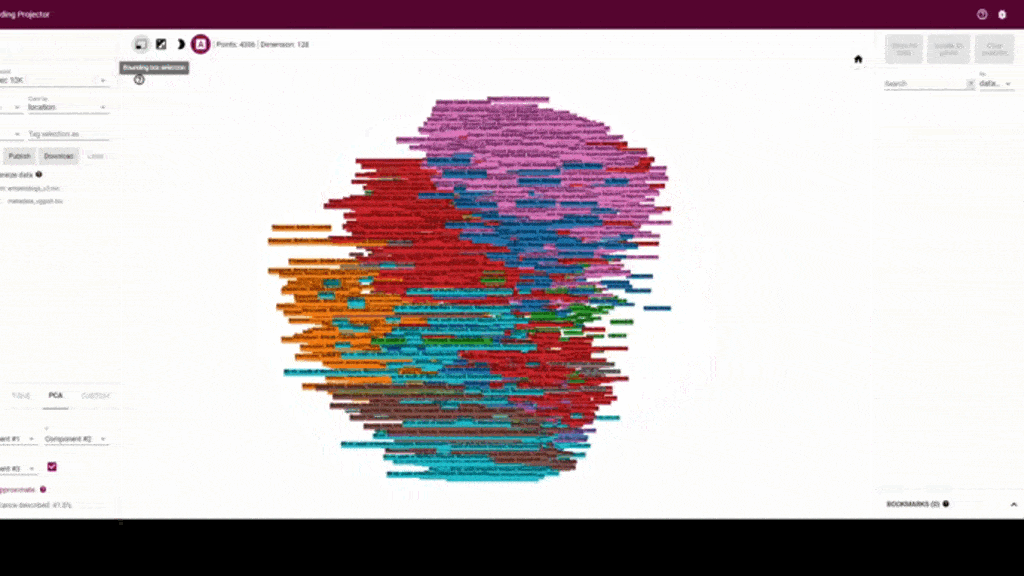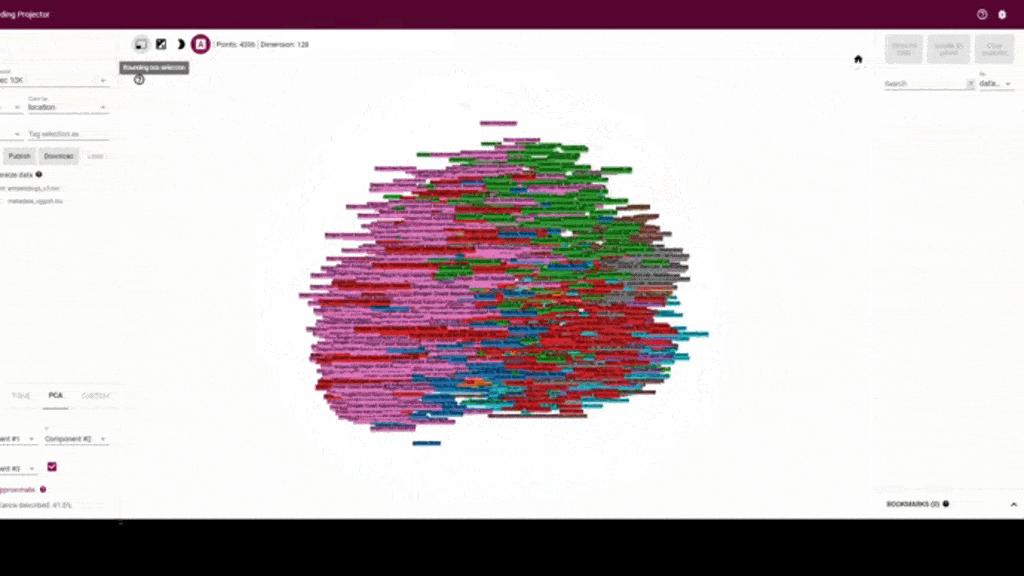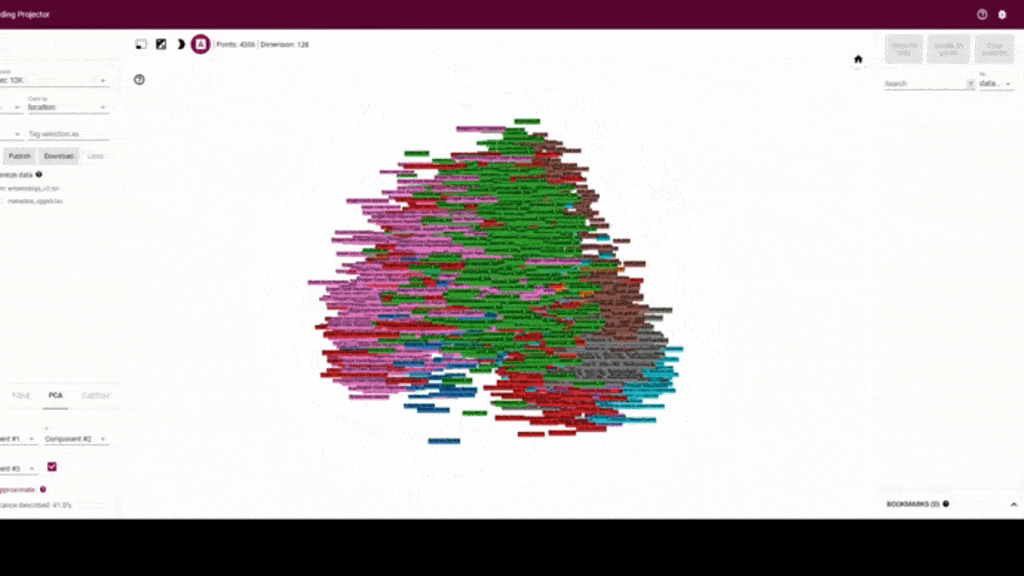
My first experiment was using the training dataset from the orcaml repo. (You can easily download it if you want to experiment yourself or feel motivated by the Orcasound mission.) You can see that apparently there are clusters with respect to the location of the recording. In order to better understand the clusters that were formed on this data that has more than 4000 audio events, we run the embeddings analysis on audio that had orca calls but also snippets of background noise.
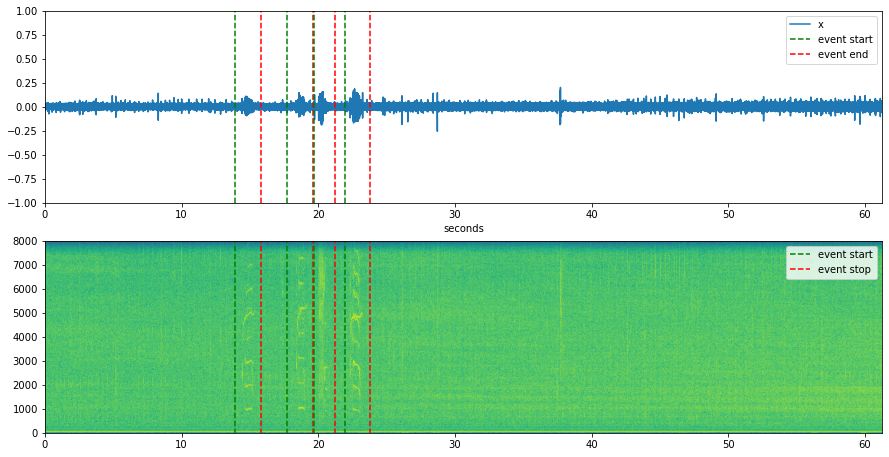
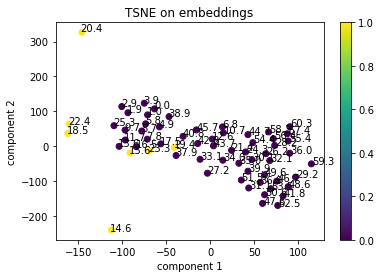
We can see from this experiment that embeddings also do a good job separating the orca calls from the background noise. Each point represents approximately one second of audio and the time segment is labeled next to each point.
One thought on “Beginning the summer with the sea sounds”