The coding period for Google Summer of Code 2020 is over. It has been three months of a lot of learning, fun, experimentation and coding.
Three months ago, I had just basic knowledge of Machine Learning. I didn’t know how to deploy an application on a server, didn’t know how to test applications, was not familiar with the typescript programming language, webpack, ORMs and a bunch of other tools used to make the process of coding webapps easier and more production ready, and I also hadn’t used Amazon Web Services. Now, I have learned all that, experimented with various products offered by AWS, like EC2, ECS and Lightsail. And I coded more than 1000 lines of code. I also met some really talented people. I even learned to containerize applications which helps to make a system modular.
You may be wondering how I learned all this; it isn’t like the mentors had a PowerPoint presentation to explain the concepts and I was taking notes. It was more like a mentor (Jessie) said that I needed to write some tests for the app, and suggested that I check a certain library. So that’s what I did; I read the documentation, or a blog, or watched a tutorial, and adapted those examples to my use case. The thing is that to be able to know what to change from those examples, you have to understand how the library that you want to use works.
The project that Kunal, the Orcasound mentors, and I have developed focused on building an active learning tool. Active Learning comes from the idea that a machine learning algorithm can perform better with less training if it is allowed to choose the data from which it learns.
The tool is a web application which we called orcaAL, visit it by clicking on the following link: https://orcasound.github.io/orcaal/.
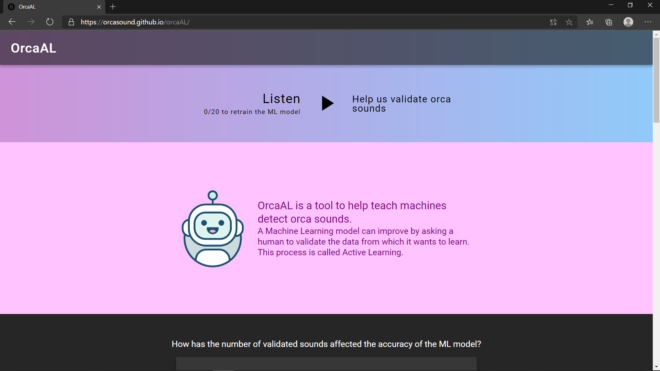
The images below show how the application ended up looking:

We expect the user to engage in labeling data to help validate the sounds about which the model is less confident. My expectation is that the user will know to select the “play” icon to help out as a citizen scientist. A funny thing about this image is that I think I spent like two hours looking for the best picture of a happy robot!

This graph is the most important one, because it indicates whether or not the ML model is improving as annotators label data. The x-axis displays dates, every point on the chart represents data about when a model was trained. The right y-axis shows the accuracy of the model, while the left y-axis represents the number of samples the model trained with. When the blue line has reached a plateau, the application’s objective would have been fulfilled, because it means that acquiring more data is likely a waste of the human validator’s efforts. Burr Settles, author of a book entitled “Active Learning,” puts it the following way: “the moment to stop learning is the point at which the cost of acquiring new training data is greater than the cost of the errors made by the current system”.

We also provide statistics after every training round. The “confusion matrix” helps us know if the model is actually performing well, it shows the ways in which the classification model is confused when it makes predictions.

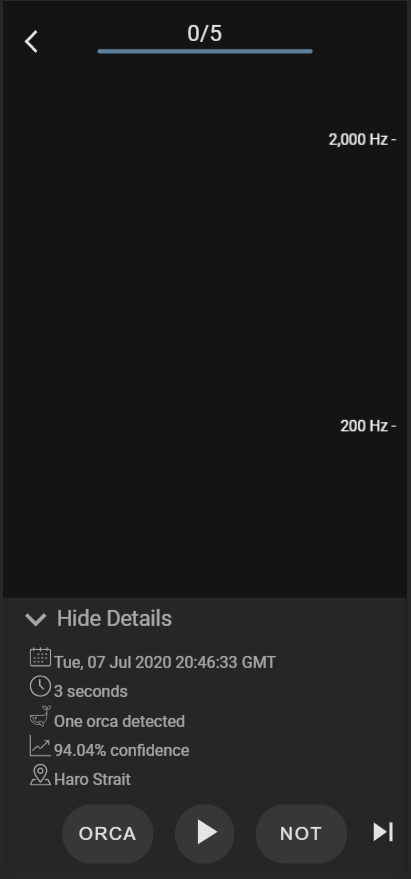
When you open the audio player by selecting the play icon on the landing page of the web app, you can view some info about the audio as you listen to a clip and visualize its spectrogram in 3D (which is a fork of chrome music lab’s spectrogram). I designed this UI with the aim of making it easy for a human validator to choose a label that characterizes the sound. In the sample that is shown above, a model predicted with 94% accuracy that it detected an orca call, this audio was recorded the 7th of July with a hydrophone located at Haro Strait. This audio has a duration of 3 seconds. In this case, the spectrogram shows only ship noise, which means that the model was wrong with its assumption and it is going to learn from this the next time it is trained.
I mentioned at the beginning of this blog post that we used docker to make the app more modular. I’d like to point out that the whole system was built in a modular way, so that it would be easy for other developers/data scientists to change whatever they want. For example, Abishek (one of my mentors) might like to use his own ML model. He would be able to do that by changing an environment variable and restarting the app, without the need to recompile the whole project.
To develop this project, Burr Settles’s Active Learning book was very helpful. For the tech-savvy, it may be interesting to know how a machine learning model might get to choose the data from which it wants to learn. We are using an algorithm that comes from Burr Settles’s book.

Basically, after the machine learning algorithm trains on labeled data, it poses queries in the form of unlabeled dataset to be labeled by a human annotator that already understands the nature of the problem. Then, those instances become part of the labeled dataset and the loop starts again with another round of training.
To choose the most uncertain subsets of the classified audio data, we are choosing the instances closest to the 0.5, as Settles states in his book that this heuristic is sufficient for a binary classification problem. Why 0.5? Given the spectrogram of an audio, the model predicts values between 0 and 1 with 0 meaning orca and 1 meaning not orca; so, a predicted value of 0.5 means that the model needs help to classify the sound.
It’s useful to know that all the code we have used and generated is open source (MIT license), and can be found on GitHub (https://github.com/orcasound/orcaAL).
The image below shows a screenshot of the AWS console’s view of a storage “bucket” that contains some sample sound files from the Orcasound hydrophone network. Other parts of the gsoc bucket contain the model and unlabeled data that may contain orca signals. Bio Acousticians like some of my mentors (Dan, Hannah and Scott), will use this new tool to generate more labeled data for the endangered Southern Resident Killer Whales, and to improve binary classification models for their calls.
The idea and our hope is that other data scientists and bioacoustics experts will use our tool, too. Research on any sound-making species could be advanced with more of the labels generated by the annotators and data scientists can explore the different versions of their model,including observing how it’s performance evolves over multiple rounds of training. All this should be easy, since each component of the active learning system is modular and the data are saved in an S3 bucket by the application.

Even though the coding period is over, the project continues, and I plan to keep on contributing to the open source community. Finally, I would like to thank the folks at Google for their support of the GSoC program and the Orcasound mentors that selected my proposal.
If you’d like to learn more about this project and my experience in it, you could also read my two other blog posts (https://www.orcasound.net/2020/07/01/gsocs-active-learning-tool-progress-after-1-month/, https://www.orcasound.net/2020/08/02/two-months-as-a-gsoc-participant-with-orcasound/).
References:
B, Settles, Active Learning, Morgan & Claypool Publishers,2012