Hey again! I’m Diego and I’m a Google Summer of Code participant with Orcasound.

We (Kunal, the mentors and I) have been working on an active learning web application for two months now. The goal of the project is to have a more accurate call detection model by increasing the size of the labeled dataset but keeping the workload of the annotators low. For the first month of the project, Kunal worked on the training of a machine learning model while I focused on the fronted of the web application and an API that would serve as an interface between the frontend and the machine learning model(s).
For this month, after some research, we were finally able to design the architecture of the system, keeping in mind that we wanted the system to be modular.
The diagram below shows the architecture of our system. We have by today a working API, the handling of raw S3 data, and the Flask Endpoint for the ML model. So, we still need to setup the Docker containers, work on a couple of issues, and develop one or two features for the system; which we’re going to do in the next month. What I like about the system is its modularity, so we could easily add more ML models if we wanted, or switch to another database, or change the spectrogram visualization library.

I’m going to quickly explain how the system works and mention why we made some of the decisions that we made.
First, unlabeled data is trimmed into three seconds mp3 clips, with which spectrograms are generated; the model is then trained on those three seconds mel-spectrograms. Both the mp3’s and spectrograms are saved in a s3 bucket. We’re using mp3 files instead of wav files because mp3 files are 10 times smaller, which reduces the storage cost and the audios load faster on the web application.
Then, the web app asks for the samples in which the model had more uncertainty; it fetches an mp3 file, and a spectrogram for the annotators is generated on the client’s side. You can take a look at the application over here: https://orcasound.github.io/orcagsoc/. Note that each sample autoloops until you classify or pause it. I chose to generate the spectrograms on the client’s side instead of using the ones that were generated for the model, just because I wanted the spectrogram to look cool.
The annotators can choose if they heard an orca or not, but also choose from which pod it was, or if it was a Bigg’s Killer whale (which Scott told us that are also heard in the Salish sea). In addition, if they didn’t hear an orca, they can select if they heard a boat, or a bird, or something else.
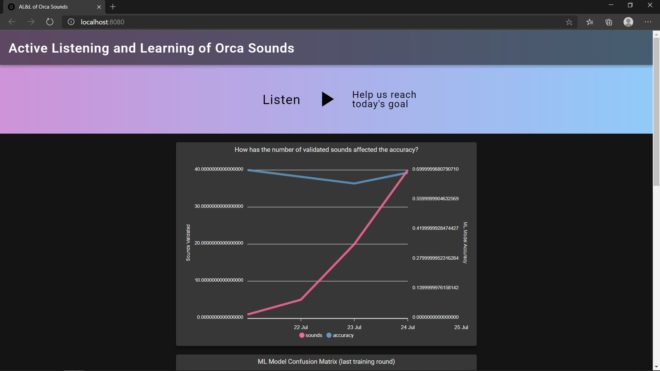
Finally, as seen in the flowchart, when the number of labels has reached our goal, the training and prediction start again.
To deal with concurrency, an audio is marked as “labeling” on the SQL database, so it can’t be accessed by any other labeler.
The most recent version of the code can be found on this GH branch: https://github.com/orcasound/orcagsoc/tree/feature/preprocess. We currently have three servers, one for the model, one for the Flask API and one for the frontend.
Microsoft Hackathon
Orcasound had the opportunity to participate in this year’s Microsoft Internal Hackathon. This means Kunal and I could participate as guests. I then decided I wanted to work on my frontend skills, that said, my primary task for the hackathon was to make the map shown below interactive.
At the end of the three days of the Hackathon, we all ended up having fun, I also could finish my task, but most important, I met some really talented people who are also committed in donating some of their time to save the orcas.

One thought on “Two months listening and learning about orca sounds”