
I’m Jorge Diego Rodríguez, student in my 4th year of B.S. in Digital Systems and Robotics Engineering at Tecnológico de Monterrey. I’m based in northeastern Mexico and I was selected as a Google Summer of Code 2020 student for Orcasound. I focused my proposal on the active learning project idea. Kunal Mehta was also selected and his proposal was on the same idea. Since we had complimentary skills and goals, we were asked to put together a joint proposal. He is focusing on the preprocessing of the data and the machine learning model, while I’m focusing on the development of the web application.
The objective is to have a machine learning model that accurately predicts if an audio file contains an orca call or not. Since there is a lack of labeled data to be able to train a very accurate model, there is a need for an active learning tool.
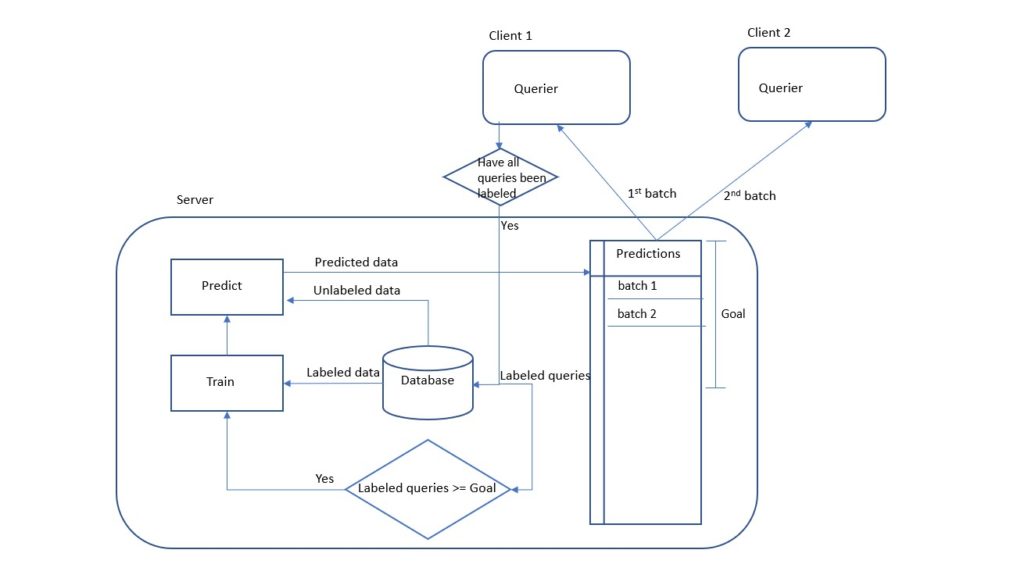
The architecture of the application that we came up with is presented below. We are basically going to train a machine learning model on labeled data and predict in a pool of unlabeled data if an audio was an orca call. Then the most uncertain predictions will be asked to be labeled by bio-acousticians and/or citizen scientists (aka the “teacher” or “oracle”). This approach reduces the job of labelers and simultaneously increases the accuracy of the model as the amount of labeled data increases.
The application consists of two pages: a homepage where the users can see statistics about the model and how humans are helping machines learn; and a querier page where the user hears an audio sample, sees its spectrogram in 3D, and then decides on a label for the sample.

The progress we have so far about the web application can be seen in the Gitghub page https://orcasound.github.io/orcagsoc where you can access the querier page by clicking on the listen button. The UI was designed to be intuitive and simple to use.
We can thank Chrome Experiments for the 3D spectrogram which makes it easier to visualize frequency, amplitude and time of a sound in one graph.

When a mouse hovers over the Orca or Not buttons, more options appear, which gives the user the ability to choose a more specific label for each audio. It isn’t needed for the current project, but I think it could be useful in the future when we have a more powerful ML model (e.g. one that is capable of classifying the ecotype, pod, or even call type based on the audio sample).

When you visit the homepage, a couple of charts are shown. The first one displays the accuracy of the model after every epoch. The second one shows the confusion matrix of the model. Both charts correspond to the last training round. The third chart plots the number of validated sounds over time.



On the frontend side, the most challenging part has been to make it work on all browsers and devices. I didn’t expect that touch devices would need different code for the hovering feature, and that some browsers support some features and other don’t. For example, Firefox doesn’t support blurred backgrounds and Edge requires you to load an empty mp3 file before loading the actual files.
A server and a database are required to make the application work. Since the algorithm for the Machine Learning model is coded in Python, we decided to use Python for the backend. More specifically, we are using the Flask framework. The code was then deployed to Heroku and we are using the Postgres database that is included with Heroku.
The most complicated thing on the backend was to make a complex query to the database using an Object Relational Mapper (ORM). I know this would’ve been easier if we weren’t using an ORM, but it was a design decision from the beginning to be able to easily switch between databases, so now we had to deal with one of the drawbacks of ORMs.
Currently, the data are dummy data; we just have 5 audio samples and the statistics data is made up. So, we are going to be working for the next month on connecting the machine learning model with the web application using an active learning framework. I finally want to mention that this project is open source, and the code and documentation can be found in its GitHub repo.
We got a little bit more technical than I thought we were going to get in this post! So, kudos to all of you that were able to follow and understand to the end.
One thought on “GSoC’s active learning tool: progress after 1 month”